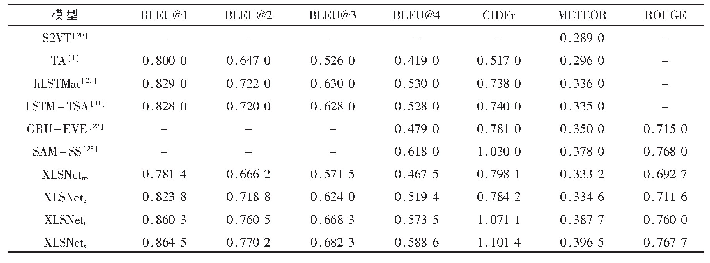
《表1 不同语义结合和主流模型结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由语义检测模型提取的视频语义特征可认为包含了视频中事物、场景以及关系信息,视频经过CNN图像分类器得到的最终1 000类的类别分布可认为是某种模式的语义信息,也是有助于语言解码的,因此本文送入解码器的语义特征si=[ti,ci],其中ti表示语义检测网络提取的语义特征,ci表示CNN分类器得到语义特征。为了验证语义属性对模型解码的影响,本文尝试了几种不同的语义特征的组合模型:XLSNetno表示没有使用语义特征,XLSNett表示只是使用了语义检测网络提取的语义特征t,XLSNetc表示只使用了CNN分类器得到的类别分布语义特征c,XLSNets表示使用了两个语义特征。为了公平比较,四个模型的实验设置完全一样。表1显示了四个模型和其他现有流行的视频描述模型的结果比较。
| 图表编号 | XD00212230400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.10 |
| 作者 | 李亚杰、关胜晓、倪长好 |
| 绘制单位 | 中国科学技术大学微电子学院、中国科学技术大学微电子学院、中国科学技术大学微电子学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}