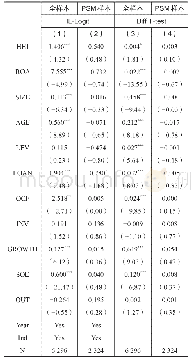
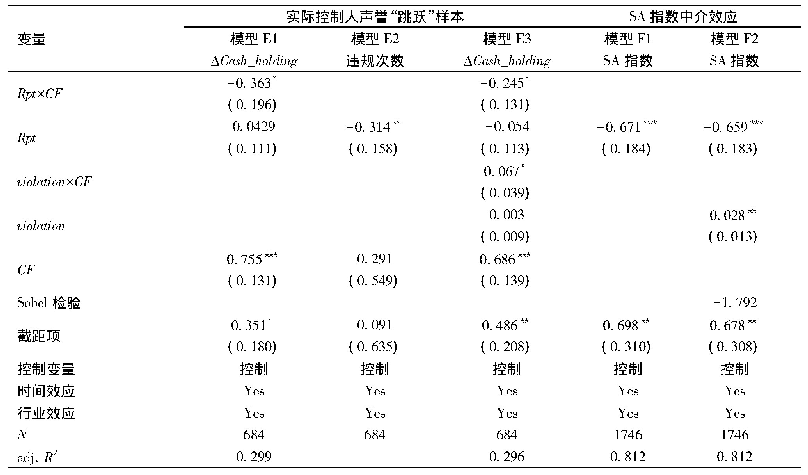
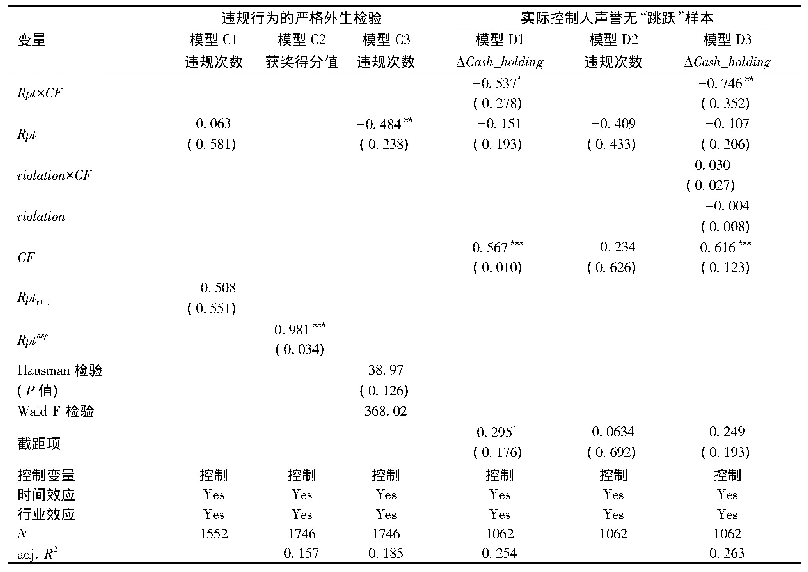
《表3 PSM检验:成为“最佳实践”:试点经验的话语建构》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
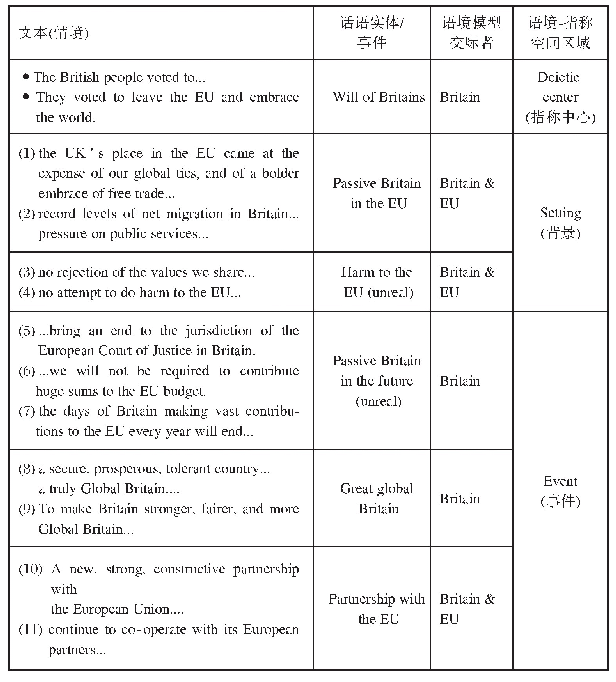
最后,构建各类需要分析的共现矩阵网络。与二模网络的构建相似,对编码完成的话语样本进行词频筛选与时间分段,之后分别将其题录信息导入SATI3.2软件,经过字段抽取、频次统计、矩阵生成等程序形成共现矩阵(Co-Occurrence Matrix)。考虑到本文数据来源的多元性,由频次直接构建的网络之间不可比,需要进一步处理数据。目前学界的处理方法主要有两种:一是计算二模网络的列模相关系数所得的相似矩阵,这类方法反映了网络各节点的活跃程度,但在大规模网络中存在适应性不佳的问题;二是假设观测网络背后存在潜在结构,通过数学方法提取观测网络背后的关联模式(陈华珊,2017),这类方法在自然科学领域得到了广泛应用。考虑到文本的概念类属本身已经是对现有文本的抽象,基于此再假设文本网络存在潜在空间则难以解释其意涵,因此,本研究采用相关系数法算出原始共现矩阵的相似矩阵,使用相似矩阵进行分析。随后,本研究测量了网络的中心势、密度、平均路径、节点数量,以及网络节点的点度、中间中心度及其作为概念类属出现的频次。最后,本研究通过Spring算法实现网络可视化,并使用Louvain算法进行聚类分析。
| 图表编号 | XD00206175200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.20 |
| 作者 | 王路昊、林海龙 |
| 绘制单位 | 电子科技大学公共管理学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}