《表2 典型的基于学习的VO》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
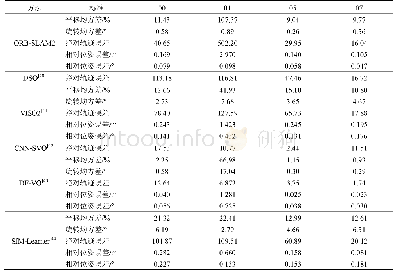
对比分析以上研究可以看出,无监督学习不需要提前标记数据集,相较于有监督学习而言可以节省很多工作量。尽管无监督的VO在位姿估计精度上仍然不及有监督的VO,但它在估计场景尺度和动态场景相机位姿估计问题上的表现优于其他方案,另外,无监督学习VO在网络设计的可操作性和无标签数据场景下的泛化能力方面也有一定的优势,而且无监督学习的VO通过位姿变换后的图像与实际图像的差异进行训练,比较符合人类的普遍认知习惯。随着无监督学习的网络的性能不断提高,无监督的VO有可能成为提供位姿信息的最理想解决方案。图5和图6分别展示了无监督学习的VO、有监督学习的VO和基于模型的VO在KIITI数据集上的平移误差和旋转误差。从图5和图6可以看出,有监督学习的VO的定位精度略优于无监督学习的VO,而基于模型的VO的定位精度一直高于基于学习的VO的定位精度。表2分有监督学习和无监督学习展示了几种典型的基于深度学习的VO。
| 图表编号 | XD00204889300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.24 |
| 作者 | 陈涛、范林坤、李旭川、郭丛帅 |
| 绘制单位 | 长安大学、长安大学、长安大学、长安大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}