《表4 样品理化指标:基于分步迁移策略的苹果采摘机械臂轨迹规划方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
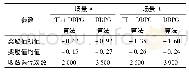
由图10a可知,随着迭代次数的增加,采摘机械臂所获奖励逐渐变大,最终达到收敛状态。由图10b可知,随着迭代次数的增加,采摘机械臂所获奖励逐渐变大,最终达到收敛状态。训练开始时基准模型的曲线奖励值起点在-1.30附近,而经过预训练的奖励曲线起点在-1.00附近,这表明经过预训练,采摘机械臂的动作策略获得了一些先验知识,具有较好的初始假设,减少了无效探索,相对于随机初始化性能有较为明显的提升。表4统计了迭代中4 000~5 000次的奖励值均值以及训练期间收敛所用迭代次数,其中基准模型为直接在三维空间中训练所得模型。
| 图表编号 | XD00204484200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 郑嫦娥、高坡、GAN Hao、田野、赵燕东 |
| 绘制单位 | 北京林业大学工学院、北京林业大学工学院、田纳西大学生物系统工程及土壤科学系、北京林业大学工学院、北京林业大学工学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}