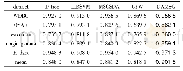
《表3 尺度上推:不同算法的F-score比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文UAMSC算法以LIBSVM为基础,以基准尺度分类结果为转换对象,实现基准尺度分类模型到目标尺度分类模型的转换。经过尺度划分,基准尺度上得到多个分类模型,不同分类模型所能提供信息具有互补性,可以多层次提供分类信息。每个分类模型学习到的信息各不相同,可以减少过拟合的风险。在尺度上推中,新生成的分类模型综合了多个分类模型信息,在一定程度上减少了数据对模型的敏感性和过多的依赖性,增强了模型的泛化性能。F-score是数据挖掘领域广泛采用的评价性能指标。F-score值越大,表示该分类算法性能越好。从表3中可以看出,UAMSC算法在不同数据集上的F-score值均在80%以上,且均高于其他分类算法,在WDBC和waveform数据集上尤其明显。在针对WDBC数据集的实验中,相对CFW,UAMSC提升了11.4%,对于仅次于UAMSC的MSCSUA,提升了3.7%。在waveform数据集上,相对D tree和MSCSUA,UAMSC分别提升了12.4%和3.2%。与WDBC数据集相比,H data的F-score值提高较少,原因在于H data有较明显的分类特性,对算法的要求比WDBC略低。通过比较不同算法的F-score平均值可以看出,UAMSC要优于其他算法,平均有4.8%的性能提升。
| 图表编号 | XD00202115200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.05 |
| 作者 | 张璐璐、赵书良、田真真、陈润资 |
| 绘制单位 | 河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学数学科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}