《表1 摘要的统计:基于优势演员-评论家算法的强化自动摘要模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在长文本自动摘要中,已有的抽取式方法抽取原文句子组成摘要,摘要的长度往往是参考摘要长度的几倍,例如基于encoder-decoder的抽取式模型Refresh[13]对数据集CNN/Daily Mail中测试集样本进行抽取,结果如表1,参考摘要往往比抽取摘要短,平均每句参考摘要13.5个词,平均每句抽取摘要27.8个词,平均抽取摘要句的长度是平均参考摘要句长度的2倍多,表明直接抽取整句作为摘要的方法将导致摘要信息冗长、不够精简。
| 图表编号 | XD00201810700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.10 |
| 作者 | 杜嘻嘻、程华、房一泉 |
| 绘制单位 | 华东理工大学信息科学与工程学院、华东理工大学信息科学与工程学院、华东理工大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |

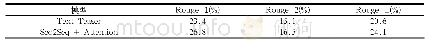



{kind=link}