《表1 实验中使用的数据集(pkb)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于推特、微博等社交工具的文本长度限制在140词,本文从公开的假新闻数据集和相关假新闻验证网站上搜集整理数据,得到一个短文本假新闻二分类数据集,并命名为pkb假新闻数据集。pkb假新闻数据集的主要来源有:politifact网站、kaggle假新闻竞赛数据集和Buzzfeed数据集。对于politifact网站上的数据,选取其中4个类别,分别是true、false、barely-true和pants-on-fire,后3个类别统一归为假新闻一类;kaggle假新闻竞赛数据集和Buzzfeed数据集按照原有数据集的真假新闻标签分别获取真假新闻数据。pkb假新闻数据集全部为不超过140个词的短文本新闻,标签为0(假,对应表1中的负例列)或1(真,对应表1中的正例列)总计13 070条数据,具体划分见表1。
| 图表编号 | XD00197686600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.10 |
| 作者 | 何韩森、孙国梓 |
| 绘制单位 | 南京邮电大学计算机学院、南京邮电大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




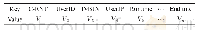

{kind=link}