《表3 本文模型与传统抽取方法的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
单位:%
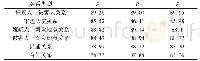
将本文模型与经典的实体识别与关系抽取模型在本文数据集上进行了如表3所示的对比实验。其中多特征组合嵌入模型(Feature-Rich Compositional Embedding Models,FCM)[18]与LINE(Large-scale Information Network Embedding)[19]为基于串行结构的实体识别与关系抽取模型:FCM将文本表示与词向量表示进行融合,然后分步进行实体识别与关系抽取;LINE则是基于网络的嵌套方法分步抽取实体及实体间关系。由实验结果可以看到,联合学习两项任务相较于串行学习效果更好。多实例联合抽取(Multi-instance Relation extraction,MultiR)模型[20]与增量集束搜索算法和结构化感知器的联合抽取算法DS-Joint[21]为联合学习模型,其中:MultiR针对远程监督的噪声问题提出了多实例的联合学习方法;DS-Joint则在标注数据集中使用结构感知器对实体与实体关系进行联合抽取。可以看出,与经典浅层联合模型相比,本文模型的F1有了近5个百分点的提升。LSTM-CRF[12]与LSTM-LSTM[12]是序列标注任务中的经典模型;LSTM-SA-LSTM-Bias[12]则将注意力机制引入LSTM-LSTM,在准确率上达到了更好的效果。与序列标注领域常用的经典编码解码模型相比,本文方案也有了一定提升;而相较于编码-解码结构的前沿模型Transformer[11],本文提出的联合深度注意力网络JointDeepAttention的F1高出了1.5个百分点。上述实验结果验证了本文模型的有效性。
| 图表编号 | XD00197684900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.10 |
| 作者 | 张心怡、冯仕民、丁恩杰 |
| 绘制单位 | 矿山互联网应用技术国家地方联合工程实验室(中国矿业大学)、中国矿业大学信息与控制工程学院、中国矿业大学物联网(感知矿山)研究中心、矿山互联网应用技术国家地方联合工程实验室(中国矿业大学)、中国矿业大学信息与控制工程学院、中国矿业大学物联网(感知矿山)研究中心、矿山互联网应用技术国家地方联合工程实验室(中国矿业大学)、中国矿业大学信息与控制工程学院、中国矿业大学物联网(感知矿山)研究中心 |
| 更多格式 | 高清、无水印(增值服务) |


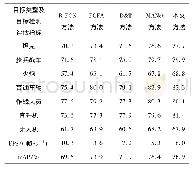
![表5 本文方法与传统方法的诊断准确率对比[24]](http://bookimg.mtoou.info/tubiao/gif/XAJT202008009_06300.gif)

{kind=link}