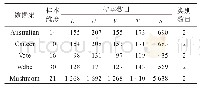
《表1 数据集统计信息:DE-ELM-SSC~+半监督分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
采用UCI数据集上的5个真实数据集进行实验:Australian Credit Approval(Australian)、Breast Cancer Wisconsin(Cancer)、Congressional Voting Records(Vote)、Wisconsin Diagnostic Breast Cander(Wdbc)和Mushroom(统计信息如表1所示)。表1中,L和U分别表示有标签训练数据集和无标签样本数据集,V和T分别表示验证和测试数据集,S表示所有数据的总和。本文实验代码采用Python编程语言,在如下配置的单机上运行:3.5 GHz CPU、8 GB内存、Windows7 64位操作系统和Python3.6.3。以最新的Tri-DE-ELM为baseline方法,并采用准确率(Accuracy)作为性能评价标准。Accuracy=(预测正确的样本数)/(预测的总样本数)。每次实验运行50次,报道平均实验结果。
| 图表编号 | XD00190601000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 庞俊、黄恒、张寿、舒智梁、赵宇海 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、武汉科技大学计算机科学与技术学院、武汉科技大学计算机科学与技术学院、东北大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}