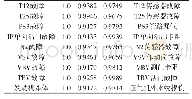
《表3 特征重要度排序:基于人工神经网络算法的2型糖尿病发病风险预测模型的构建》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于人工神经网络算法的2型糖尿病发病风险预测模型的构建》
注:FPG.空腹血糖;OGTT.口服葡萄糖耐量试验;BMI.体质指数。
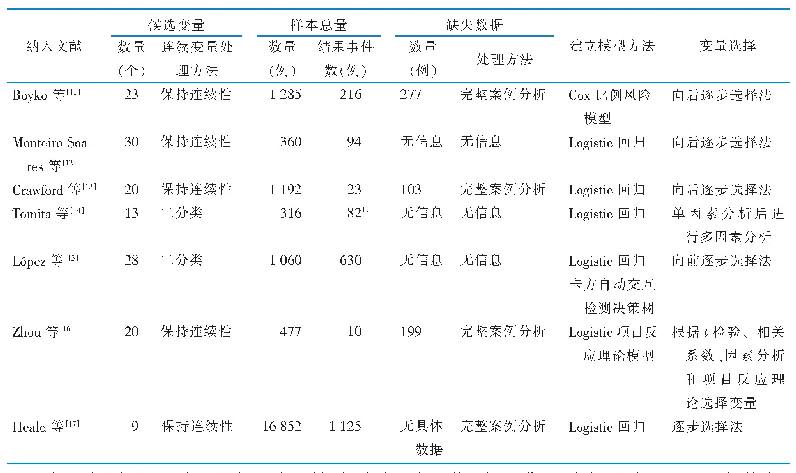
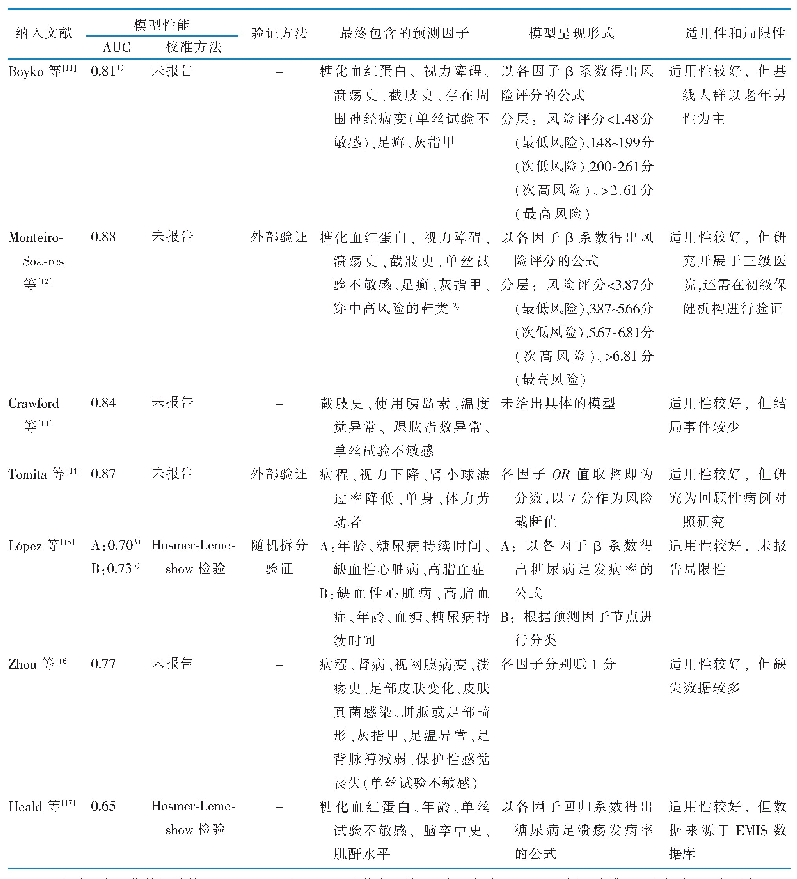
糖尿病作为多发的严重慢性病,患病率呈现逐年上升趋势。通过特定的数学模型进行个体糖尿病风险预测,为采取预防干预措施提供个性化建议,有助于提高人群的健康水平和生活质量。2016年Hu等[19]总结了既往基于亚洲人群建立的2型糖尿病风险评分,这些研究均采用logistic回归或Cox回归,曲线下面积(AUC)在0.66~0.91之间。验证了例如年龄、性别、BMI、FPG和TG等具有预测能力的危险因素。采用传统统计学模型的研究中,模型和变量具有较好的解释性,建模后可以得到回归系数和OR或HR值,从而量化危险因素对结局事件的影响并应用于糖尿病风险预测。另外建模结果可以公式化,适用于软件编程等实际应用过程。但传统统计模型难以处理高维数据,且对数据分布有较严格的假设。因此本研究使用ANN建立模型,ANN可以处理高维度数据,具有较强的非线性映射能力,可以合理预测输入变量和输出变量之间的关系并进行修改、容错等[20]。目前国内外已有一些研究采用ANN建立糖尿病的诊断或风险预测模型,预测效果较好,准确率均在86.00%以上[6,21-22]。然而ANN的劣势在于,作为一种“黑箱”算法,研究者很难解释输入特征与研究结局之间的关系。ANN添加的神经元和层数越多,解释和确定ANN中变量的效应大小和方向就变得愈发困难。但本文中使用了新近开发的特征重要度排序算法计算变量的置换重要度,因此可以比较建模和验证过程中各变量对结局事件的影响大小。随着可解释神经网络(explainable neural networks)的发展,神经网络的“黑箱”正在被打开,该模型的结构和设计方式增加了建模所用的特征及函数的可解释性,从而使神经网络更好地应用于医疗领域。本研究在模型中加入了SNPs信息。由于糖尿病等复杂疾病相关基因位点数目众多,且多为微效基因,判断基因序列变异和复杂疾病之间的关系相对困难。因此既往常用多基因风险评分(polygenic risk score,PRS)进行研究,PRS可以综合多个SNPs的微弱效应,分析遗传序列变异与复杂疾病表型之间的关系。PRS的构建基于多基因模型,假定疾病的遗传效应等于各个位点的效应之和,算法有简单的PRS和加权PRS。PRS基于线性参数回归模型,该模型包含了严格的假设,包括自变量效应的可加性和独立性、底层数据的正态分布以及各观测间不相关。这些假设可能并不适用于复杂多基因遗传疾病,导致预测效力大幅度降低,同时线性加性回归模型也无法解释相关等位基因之间的复杂交互作用[23-24]。因此,有研究发现基于线性加性回归的建模导致PRS倾向于偏倚和无效预测[23-25]。相比之下,机器学习算法采用多变量、非参数方法,可使用非正态分布和强相关数据建立稳健的模型,识别复杂模式[26-27]。所以本研究直接纳入已通过亚洲人群验证的与2型糖尿病相关的SNPs,通过计算输入变量的特征重要度,发现单个SNP位点对于糖尿病发病预测也有着重要作用,验证了既往糖尿病遗传风险研究成果,也可为进一步研究提供科学假设。
| 图表编号 | XD00180602000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.15 |
| 作者 | 车前子、郑启文、陈思、马雨佳、周泽宸、武轶群、吴涛、胡永华、陈大方 |
| 绘制单位 | 北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系、北京大学公共卫生学院流行病与卫生统计学系 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}