《表4 本文方法匹配核查结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于中文分词的加权地理编码在COVID-19疫情防控空间定位中的应用》
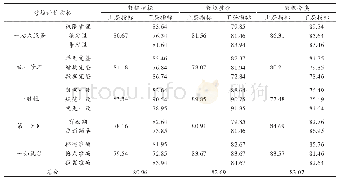
由于任务的特殊性,本文认定只要有返回结果都看作是地址的最优匹配结果,没有返回结果的作为本文方法漏匹配的数据。本文以匹配到小区、村为人工核查的匹配标准,采用人工检查的方法核对了疫情地址的所有匹配情况,并将实际匹配结果作为方法有效性评价的基础。表4统计了本文匹配方法得到的正确匹配数、错误匹配数、模糊匹配数、漏匹配数和匹配准确率。其中,模糊匹配数为没有明确社区、小区地址、没有道路编号以及村镇等地址,漏匹配数为没有识别出结果的数据。人工核查发现,原地址中存在大量拼音错误及记录错误的情况。本文方法因考虑了拼音问题、病人主观意愿(如不太愿意提供更详细地址)、人工记录(多音字、手写笔误、简化记录)等情况,减少了漏匹配和错误匹配的情况。这是因为本文方法通过建立地址层级模型,考虑了特征词的重要程度,并依据汉字拼音、别名等原则,从而降低了错误匹配和漏匹配的情况,提高了匹配的准确率。
| 图表编号 | XD00173651600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.05 |
| 作者 | 彭明军、李宗华、刘辉、孟成、李勇 |
| 绘制单位 | 武汉市自然资源和规划信息中心、武汉市政务服务和大数据管理局、武汉市自然资源和规划信息中心、武汉市自然资源和规划信息中心、武汉大学测绘遥感信息工程国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}