《表4 关系抽取模型训练数据集描述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
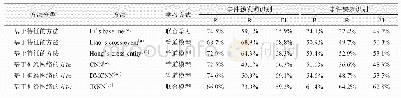
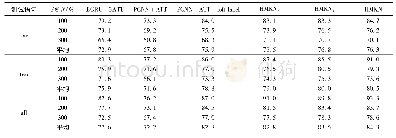
本文使用的中文关系抽取数据集来自清华大学林衍凯等[13]公开的中英文双语关系抽取数据集,这是目前最大的中文关系抽取数据集。这个数据集中,中文实例是中文百度百科对齐wikidata生成的,英文实例是英文wikipedia对齐wikidata生成的。数据集中wikidata的关系事实分成3部分,分别用来作为训练集、验证集和测试集,包括NA(两个实体之间没有关系)在内,总共有176种关系,100多万条语句。表4是其中中文数据集的统计信息。遵循PCNN_ATT[3]的工作,本文也使用PR曲线作为评估指标。PR曲线就是以查准率Precision和查全率Recall为轴,取不同阈值画的一条曲线。曲线下的面积称为PR?auc,auc越大,或者曲线越接近右上角(查准率和查全率均为1),模型就越好。
| 图表编号 | XD00170137200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 刘娜娜、程婧、闵可锐、康昱、王新、周扬帆 |
| 绘制单位 | 复旦大学计算机科学技术学院、上海智能电子与系统研究院、复旦大学计算机科学技术学院、上海智能电子与系统研究院、上海秘塔网络科技有限公司、微软亚洲研究院、复旦大学计算机科学技术学院、上海智能电子与系统研究院、复旦大学计算机科学技术学院、上海智能电子与系统研究院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}