《表4 协变量匹配前后偏差绝对值的分布特征》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:*、**、***分别代表10%、5%、1%的显著性水平。
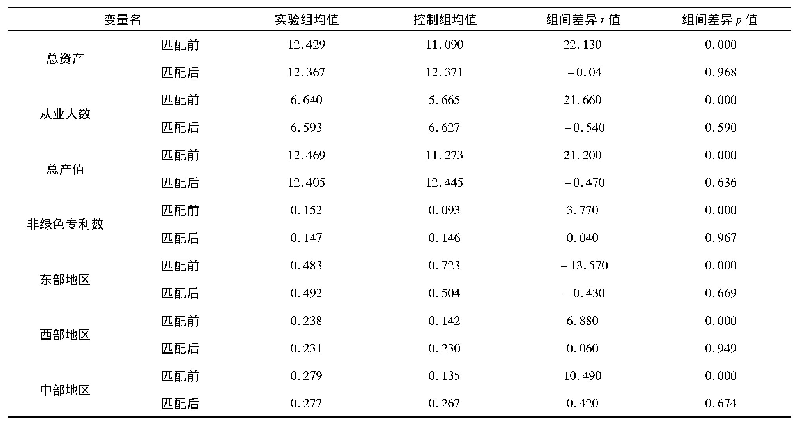
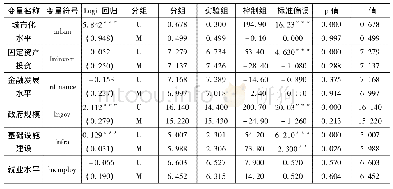
企业的专利申请数量受到其他一些变量的影响,为了消除其他控制变量的影响和样本自我选择的效应,本文采用倾向得分匹配的方法来估计政府创新补助对企业专利的平均处理效应。表4为选取的协变量在匹配前后的平行条件假设检验结果。可以看出,处理组在进行对照处理后,匹配的标准偏差都降到了10%以内,说明所选择的匹配协变量和匹配方法是合适的,经过倾向得分匹配后获得政府创新补助的企业和未获得政府创新补助的企业样本不存在显著差异。平衡性假设得到满足也意味着以此为基础的倾向得分匹配估计结果是可信的。图2显示了各变量标准化偏差在匹配前后的变化,可以直观地看出,匹配后绝大多数变量的标准化偏差缩小了;结合倾向得分的共同取值范围也可发现,大多数观测值均在共同取值范围内。
| 图表编号 | XD00145443700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 余谦、童佳子 |
| 绘制单位 | 武汉理工大学经济学院、武汉理工大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}