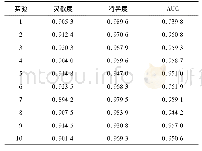
《表1 对模型进行10次重复实验的灵敏度、特异度和AUC值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了检验所建立癌症风险指标,将数据随机分为2组:训练组(60%)和检验组(40%),癌症患者和非癌症人群都以同样的比例进行数据分组。首先,计算数据中所有人的相对熵指标S,通过比较癌症人群和非癌症人群相对熵指标的分布可以看到2组人群的相对熵分布有明显的区别,癌症人群的熵比非癌症人群高,显示出更高的无序性(图3A)。然而,仅仅通过相对熵还不能很好地区分癌症高风险分群。然后,通过训练组数据得到综合指标模型,可以看到综合指标可以大大改善了相对熵指标。根据所得到的模型结果对检验组进行分析,结果显示对于癌症患者人群,高风险占91.66%,中度风险占1.04%,低度风险占7.30%。而对于非癌症人群,高风险占2.18%,中度风险占1.52%,低度风险占96.30%(图3B)。如果以该风险值作为二分类依据,把高风险认为是癌症患者,则对应的灵敏度为0.901 5,特异度为0.873 1。此外,根据上面所定义的癌症风险值Risk可以得到相应的ROC曲线下面积(AUC)为0.967 7(图3C)。为了验证模型的鲁棒性,重复上述过程,每次选取不同的训练组和检验组,所得到的灵敏度、特异度和AUC值如表1所示,显示对不同训练组所得到的模型参数有一定的鲁棒性。
| 图表编号 | XD00144005000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.10 |
| 作者 | 雷锦誌、张晗、李永志、康熙雄 |
| 绘制单位 | 清华大学周培源应用数学研究中心、北京航天总医院健康管理中心、北京航天总医院信息处、首都医科大学附属北京天坛医院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}