《表1 VUA语料分布情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
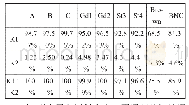
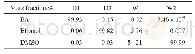
VUA(VU Amsterdam Metaphor Corpus)[9]是隐喻识别任务中目前公开的最大的人工标注的,跨领域的比喻性语言语料,由四大类文本组成,即学术文本、小说文本、新闻文本、对话文本,语料包含2626个段落(
标签),16000多个句子(| 图表编号 | XD00140379200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.05 |
| 作者 | 吴亚强 |
| 绘制单位 | 四川大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |
VUA(VU Amsterdam Metaphor Corpus)[9]是隐喻识别任务中目前公开的最大的人工标注的,跨领域的比喻性语言语料,由四大类文本组成,即学术文本、小说文本、新闻文本、对话文本,语料包含2626个段落(
标签),16000多个句子(| 图表编号 | XD00140379200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.05 |
| 作者 | 吴亚强 |
| 绘制单位 | 四川大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}