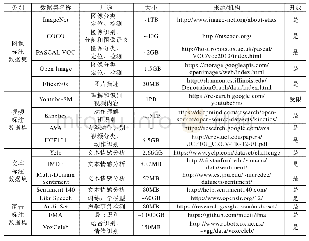
《表2 部分常用的标注数据集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文将标注数据集划分为图像、视频、文本和语音标注数据集这4大类,表2描述了这些数据集的来源、用途和特性.ImageNet、COCO和PASCAL VOC是3个典型的图像标注数据集.它们广泛应用于图像分类、定位和检测的研究中.由于ImageNet数据集拥有专门的维护团队,而且文档详细,它几乎成为了目前检验深度学习图像领域算法性能的“标准”数据集.COCO数据集是在微软公司赞助下生成的数据集,除了图像的类别和位置标注信息外,该数据集还提供图像的语义文本描述.因此,它也成为评价图像语义理解算法性能的“标准”数据集.Youtube-8M是谷歌公司从YouTube上采集到的超大规模的开源视频数据集,这些视频共计800万个,总时长为50万小时,包括4 800个类别.Yelp数据集由美国最大的点评网站提供,包括了470万条用户评价,15多万条商户信息,20万张图片和12个城市信息.研究者利用Yelp数据集不仅能进行自然语言处理和情感分析,还可以用于图片分类和图像挖掘.Librispeech数据集是目前最大的免费语音识别数据库之一,由近1 000h的多人朗读的清晰音频及其对应的文本组成.它是衡量当前语音识别技术最权威的开源数据集.
| 图表编号 | XD00136456500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 蔡莉、王淑婷、刘俊晖、朱扬勇 |
| 绘制单位 | 云南大学软件学院、复旦大学计算机科学技术学院、云南大学软件学院、云南大学软件学院、复旦大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



![表2 部分依存关系标注集[15]](http://bookimg.mtoou.info/tubiao/gif/SJSJ202005033_05600.gif)
{kind=link}