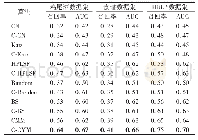
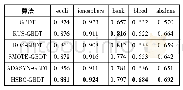
《表1 三个数据集上的召回率和AUC》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本实验在使用矩阵分解获取低维表达时,鸡尾酒、食谱和DBLP数据集的基矩阵的秩分别设定为r=4,15,50,在使用K-means算法对鸡尾酒、食谱和DBLP数据聚类时簇的数目分别设定为k=5,11,37(此时,聚类结果的轮廓系数最大,见3.4节),在每个簇中随机选取50%的超链路作为训练集,剩余50%的超链路作为测试集。随机生成的超链路数目与测试集中的超链路数目相等。测试集中的超链路与随机生成的超链路合并构成候选集。每种算法分别在原始数据和聚类获得的簇上进行预测,计算各种算法的召回率和AUC。使用CMM算法对三个数据集的原始数据进行矩阵分解时,鸡尾酒、食谱和DBLP数据集的基矩阵的秩分别设置为10、30、80;使用C-CMM算法对三个数据集的各个簇进行矩阵分解时,各个簇的矩阵的秩分别设为5、10、30。表1展示了所有算法对于三种数据集的预测结果,最好的实验结果用粗体进行表示。
| 图表编号 | XD00133784500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.10 |
| 作者 | 齐鹏飞、周丽华、杜国王、黄皓、黄通 |
| 绘制单位 | 云南大学信息学院、云南大学信息学院、云南大学信息学院、云南大学信息学院、云南大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}