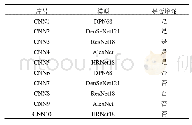
《表2 数据增强实验结果对比(识别率)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
从表2可以看出,本文的数据增强方法能够有效地提高模型的识别精度,与未增强的相比约有4%左右的提升,与传统方法相比在mobilenet_v2上有更好的表现。然而,本文方法扩充之后的数据量比传统方法少很多,而Xception具有更多的参数,对数据量的要求更高,因此本文方法在Xception上的表现比传统方法略差一点。考虑到本文数据增强方法对比传统方法在CK+上扩充的数据不多,实际操作中可将本文方法与传统方法相结合来获取更多的生成样本。从实现成本来看,本文方法需要事先训练一个GAN模型,在本文的硬件环境下大约需要训练26 h才能达到预期效果,调整输入图像大小和采用迁移学习进行参数初始化,可以将训练时间控制在2 h以内。与传统方法相比,这无疑增加了很多工作量,然而配对型数据采集困难,与人工采集相比,本文方法极大地节约了人力成本。
| 图表编号 | XD00119704800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.15 |
| 作者 | 孙晓、丁小龙 |
| 绘制单位 | 合肥工业大学情感计算与系统结构研究所、合肥工业大学计算机与信息学院、合肥工业大学情感计算与系统结构研究所、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}