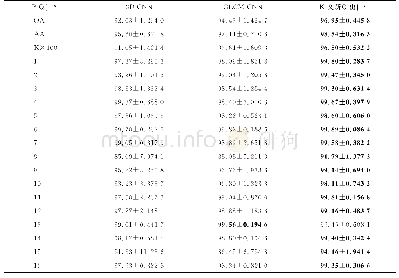
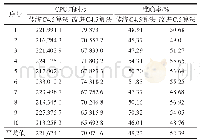
《表1 0“阶跃式”滑坡数据集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《“阶跃式”滑坡突变预测与核心因子提取的平衡集成树模型》
建立所有变量总和的“阶跃式”滑坡数据库,总数据集按3∶1划分为训练集和测试集,其中训练集根据不同过采样比率参数合成新的样本集用于集成树训练使用,测试集不参与模型的训练过程用于评估训练模型对于新数据的泛化表现。如表10所示,数据集中样本数目分布严重不平衡,直接用于传统分类算法必将导致训练结果更倾向于稳定类,对突变类学习效率降低。因此,在数据层面对目标变量进行平衡优化是提升突变信息学习效率的突破点。
| 图表编号 | XD00109308800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 何少其、刘元雪、梁叶、刘娜、赵久彬 |
| 绘制单位 | 陆军勤务学院岩土力学与地质环境保护重庆市重点实验室、重庆市地质矿产测试中心、陆军勤务学院岩土力学与地质环境保护重庆市重点实验室、重庆市地质矿产测试中心、重庆长江勘测设计院有限公司、重庆市地质矿产测试中心、陆军勤务学院岩土力学与地质环境保护重庆市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}