《表2 算法识别精度统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
首先,基于iLIDS数据集样本,训练度量模型。在模型训练的过程中,一半个体作为训练样本,另一半作为测试样本。然后将基于iLIDS数据库训练得到的度量模型,通过迁移度量学习模型将度量模型迁移到VIPeR数据集。基于VIPeR数据库的测试结果如表2和图3所示,图中给出了本文算法以及多种对比算法(SLD2L[18]、RDC[12]、ITML[11]、KISSME[14]、XQDA[8]和MLAPG[19])识别精度的CMC曲线。为确保对比实验结果的公平性,本文采用常见的测试方案,进行10次重复独立实验并计算识别精度的平均值作为最终的识别精度评价指标。在行人再识别任务中,与其他分类和识别任务不同,关心的不仅仅是距离最近的样本,对于排名比较靠前的结果都十分关心。因此,通过CMC曲线中选取了rank-1、rank-5、rank-10和rank-20共4个指标作为评价算法识别精度的依据,分别表示排名前1、5、10、20的正确识别结果所占全部识别结果的比率。从表中数据可以清楚地看出,本文算法在所有指标上均取得了最优的识别精度,尤其在rank-1的识别精度上,相较于MLAPG算法精度提升了5.79%,达到了46.14%。同时,本文算法在rank-5、rank-10和rank-20等指标上的识别精度也达到了最好的水平。同时,对于参数α,通过仿真实验,取α=0.2时模型的识别精度表现最好,因此本文中取α=0.2。
| 图表编号 | XD00102818900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.15 |
| 作者 | 宋丽丽 |
| 绘制单位 | 成都理工大学工程技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




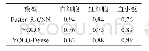
{kind=link}